
Google Research has published a compression algorithm that reduces AI memory usage by 6x with zero accuracy loss. The internet is calling it “Pied Piper.” The semiconductor market lost billions in hours. Here is what TurboQuant actually does, why it matters, and what it changes.
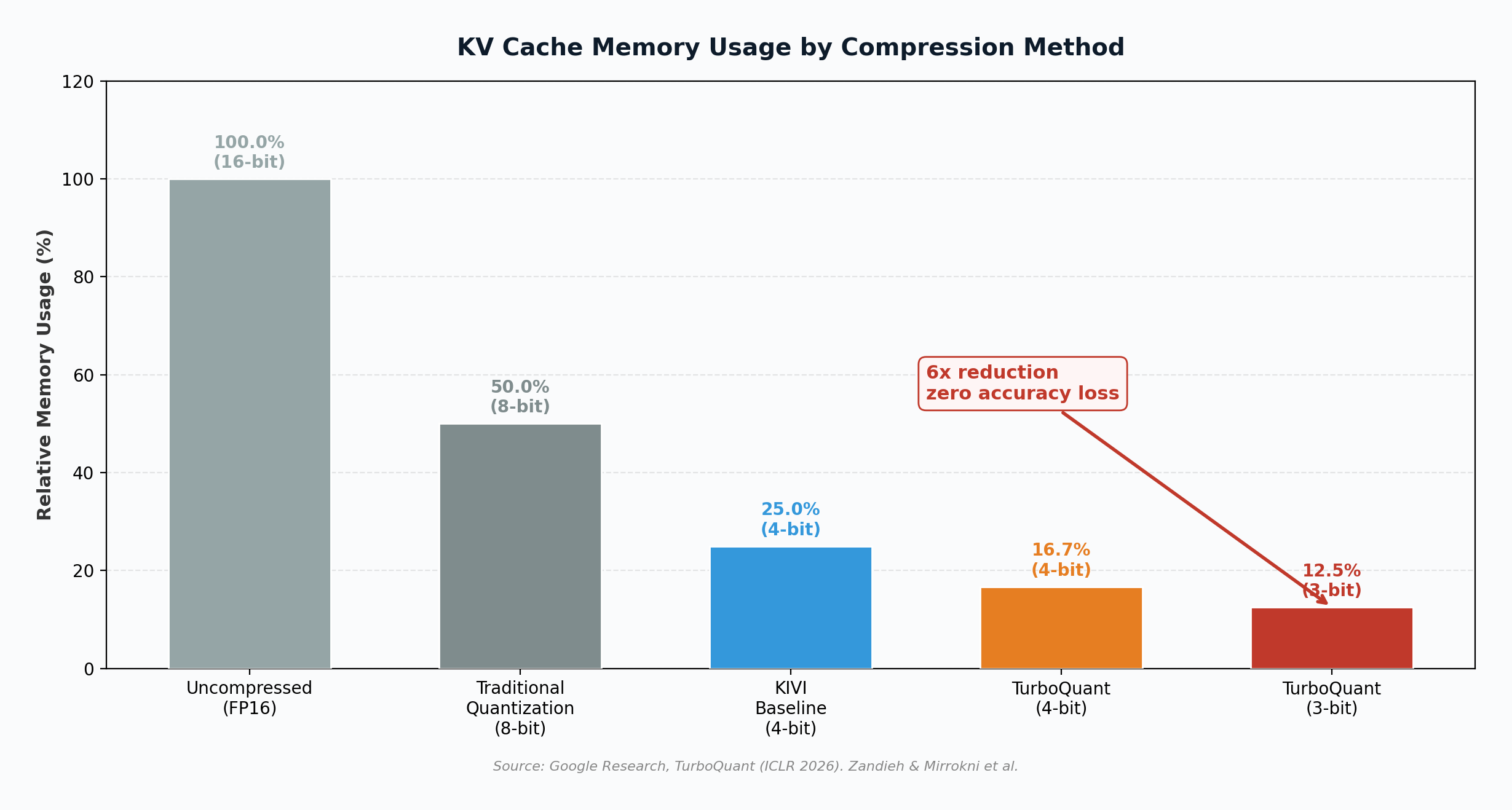
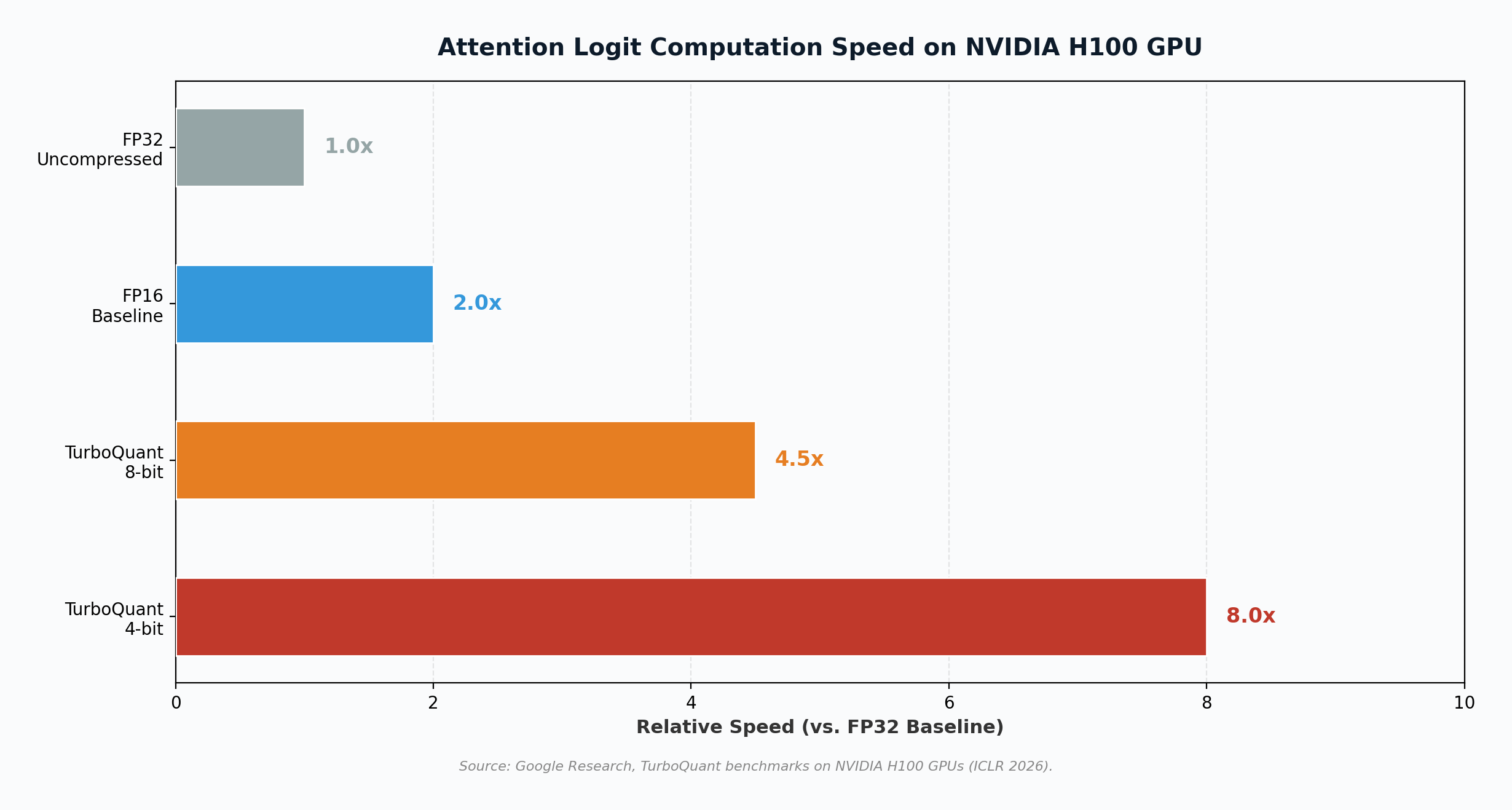
On March 25, 2026, Google Research published TurboQuant, a compression algorithm that addresses one of the most expensive bottlenecks in deploying large language models: the key-value (KV) cache, the high-speed memory structure that stores an AI model’s working context during inference. The algorithm compresses KV cache data to just 3 bits per value, down from the standard 16, reducing memory requirements by at least 6x while delivering up to 8x faster attention computation on NVIDIA H100 GPUs, all with zero measurable accuracy loss (Zandieh & Mirrokni, 2026). The paper, co-authored by Google research scientist Amir Zandieh and Google VP Vahab Mirrokni along with collaborators at Google DeepMind, KAIST, and New York University, will be presented at the International Conference on Learning Representations (ICLR) 2026 (The Next Web, 2026). Within 48 hours of the announcement, memory chip stocks from Samsung to Micron dropped 5% to 11%, the Philadelphia Semiconductor Index slid 4.8%, and Cloudflare CEO Matthew Prince called it “Google’s DeepSeek moment” (CNBC, 2026).
What Is TurboQuant?
To understand TurboQuant, it helps to understand the problem it solves. Large language models like Gemini, GPT, and Llama process information through a mechanism called attention, which requires the model to compare each new piece of input against everything it has already processed. To avoid recomputing this comparison from scratch with every new token, models store previously computed data in a key-value (KV) cache. This cache is essentially the model’s working memory (Tom’s Hardware, 2026).
The problem: as context windows grow longer, the KV cache grows linearly, consuming massive amounts of GPU memory. For a model processing a million-token context, the KV cache alone can consume dozens of gigabytes of high-bandwidth memory (HBM). This is often the binding constraint in production AI systems, not model quality or compute speed, but raw memory (Help Net Security, 2026).
Traditional compression methods (vector quantization) can help shrink the cache, but they carry an overhead cost: they must store small quantization constants alongside the compressed data, typically adding 1 to 2 extra bits per value. This overhead partially defeats the purpose and compounds as context windows expand (Tom’s Hardware, 2026). TurboQuant eliminates this overhead entirely through a mathematically elegant two-stage process.
Technical Architecture: How It Works
TurboQuant combines two complementary algorithms, each solving a different piece of the compression puzzle. The combined system builds on two earlier papers from the same research group: QJL, published at AAAI 2025, and PolarQuant, which will appear at AISTATS 2026 (The Next Web, 2026).
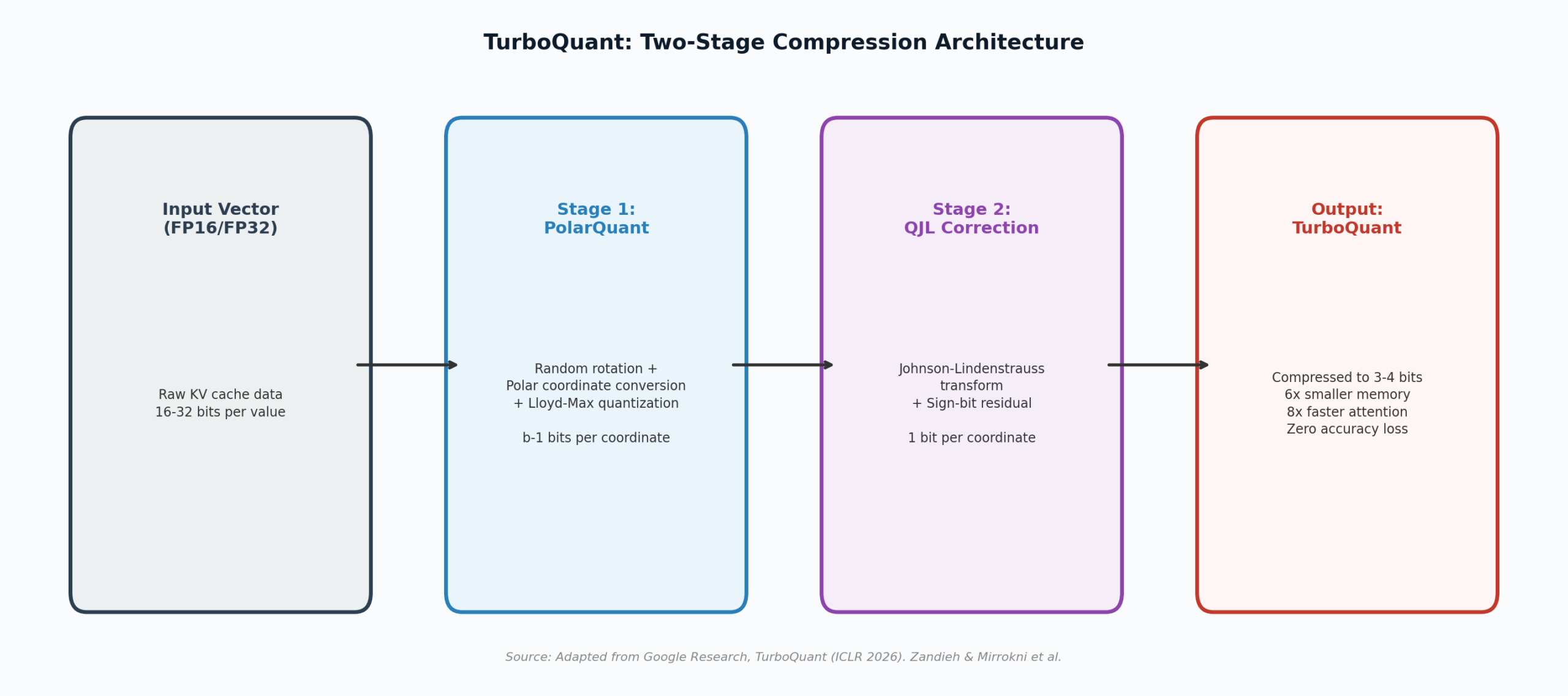
Stage 1: PolarQuant
The first stage handles the primary compression. PolarQuant applies a random orthogonal rotation to the input vector (a standard mathematical transformation that preserves all geometric relationships), then converts the data from Cartesian coordinates to polar coordinates. Instead of storing position along each axis independently (x, y, z), PolarQuant expresses each vector as a radius (magnitude) and a set of angles (direction). Because the angular distributions after rotation are predictable and concentrated, PolarQuant can skip the expensive per-block normalization step that conventional quantizers require. It applies precomputed optimal Lloyd-Max scalar quantizers to the angles, achieving near-optimal compression with zero overhead from stored quantization constants (Tom’s Hardware, 2026; Zandieh & Mirrokni, 2026).
The key insight: by applying a random rotation first, the algorithm makes the data distribution predictable before it ever sees the actual values. This means the optimal compression codebook can be precomputed once, offline, before the first token arrives. No per-block calibration. No dataset-specific tuning. The quantizer is ready before the model starts running (Help Net Security, 2026).
Stage 2: Quantized Johnson-Lindenstrauss (QJL)
The second stage corrects the small residual error left over from PolarQuant. QJL takes the quantization residual (the difference between the original and compressed data), projects it through a random Gaussian matrix, and stores only the sign of each projected component: positive or negative. That is one bit per dimension of the projection. This single-bit correction makes the combined inner product estimate provably unbiased, meaning it eliminates the systematic errors that would otherwise accumulate during attention score calculations (The Next Web, 2026).
The total cost: b bits for PolarQuant plus 1 bit for QJL correction, yielding 3 to 4 effective bits per coordinate. The algorithm operates near known theoretical lower bounds for quantization distortion, a property the authors describe as making it “dependable for large-scale, production-grade systems” (Zandieh & Mirrokni, 2026).
| Property | Traditional Quantization | TurboQuant |
|---|---|---|
| Bits per value | 4-8 bits + overhead | 3-4 bits, zero overhead |
| Memory reduction | 2-4x | 6x+ |
| Accuracy loss | Measurable degradation | Zero (provably unbiased) |
| Training required | Often requires fine-tuning | Training-free, data-oblivious |
| Dataset calibration | Required per model/dataset | None needed |
| H100 speedup (attention) | Moderate | Up to 8x (4-bit mode) |
Benchmark Results: The Evidence
Google evaluated TurboQuant across five standard long-context benchmarks: LongBench, Needle In A Haystack, ZeroSCROLLS, RULER, and L-Eval, using open-source models from the Gemma, Mistral, and Llama families. At 3 bits per value, TurboQuant matched or outperformed KIVI, the current standard baseline for KV cache quantization published at ICML 2024, across all tasks including question answering, code generation, and summarization (Tom’s Hardware, 2026).
On Needle In A Haystack evaluations, which test a model’s ability to retrieve specific information buried in extremely long contexts, TurboQuant achieved perfect recall while operating at just one-sixth of the original memory footprint. The algorithm also demonstrated strong performance in vector search applications: evaluated against Product Quantization and RabbiQ on the GloVe dataset, TurboQuant achieved the highest 1@k recall ratios despite those baselines relying on larger codebooks and dataset-specific tuning (Zandieh & Mirrokni, 2026).
How This Changes AI
TurboQuant’s impact on AI development and deployment operates across several dimensions simultaneously.
Longer context windows become practical. The KV cache has been the primary memory constraint preventing models from processing extremely long inputs. With a 6x memory reduction, a model that previously maxed out at a 128K-token context on a single GPU could theoretically handle 768K tokens on the same hardware. This unlocks use cases in document analysis, legal review, code understanding, and scientific research that were previously impractical (TechCrunch, 2026).
Smaller hardware can run larger models. Organizations that could only run smaller models on their available GPU infrastructure can now deploy significantly larger models within the same memory envelope. This is particularly transformative for enterprises running AI on-premises, where GPU memory is the binding constraint. TurboQuant’s training-free, data-oblivious design means organizations can apply it to existing models without retraining, immediately extracting more capability from their current hardware (Pulse 2.0, 2026).
Inference costs drop substantially. For hyperscalers like Google, Amazon, and Microsoft, inference (running trained models to serve user requests) is the dominant and fastest-growing cost in AI operations. Reducing memory requirements by 6x means each GPU can serve more concurrent users, directly compressing the cost per query. Google itself stands to save billions in internal infrastructure costs (Chronicle Journal, 2026).
Key Insight
TurboQuant is training-free and data-oblivious. Organizations can apply it to any existing model, from any provider, without retraining or fine-tuning. This is not a technique that benefits only Google. It is immediately deployable across the entire AI ecosystem, and within days of publication, open-source Triton kernel implementations appeared for both H100 and A100 GPUs (Search Engine Land, 2026).
How This Helps the Market
The market implications of TurboQuant extend well beyond Google’s own infrastructure. The algorithm fundamentally restructures the economics of AI deployment across several layers of the technology stack.
AI becomes accessible to more organizations. By dramatically reducing the memory required for inference, TurboQuant lowers the capital expenditure barrier for AI adoption. Enterprises, universities, healthcare systems, and government agencies that were priced out of deploying large models can now do so on more modest hardware. As Kim Dong-won, head of research at KB Securities, noted: “Low-cost AI technologies such as TurboQuant are likely to lower barriers to adoption and significantly expand overall demand” (Korea Herald, 2026).
Edge AI and local deployment accelerate. Running AI models locally, on laptops, phones, or edge devices, has been constrained primarily by memory limitations. A 6x reduction in working memory makes local inference significantly more viable, enabling privacy-preserving AI applications that never send data to the cloud (ibl.ai, 2026).
Vector search and retrieval systems improve. TurboQuant also applies to vector search, the technology underlying semantic search, recommendation engines, and retrieval-augmented generation (RAG) systems. Google reports that TurboQuant enables faster similarity search with near-zero indexing time, which could improve the speed and reduce the cost of search infrastructure broadly (Search Engine Land, 2026).
The Market Shock: Billions Erased in Hours
The semiconductor market’s reaction to TurboQuant was swift and severe. Within 48 hours of the announcement, memory chip stocks experienced significant declines. SK Hynix fell 6.2%, Samsung Electronics dropped 4.7%, Micron Technology declined 7%, and Sandisk plunged 11%. NVIDIA also fell 4.2%, while the Philadelphia Semiconductor Index slid 4.8%. Alphabet (Google’s parent) was the notable exception, rising modestly (CNBC, 2026; Korea Herald, 2026).
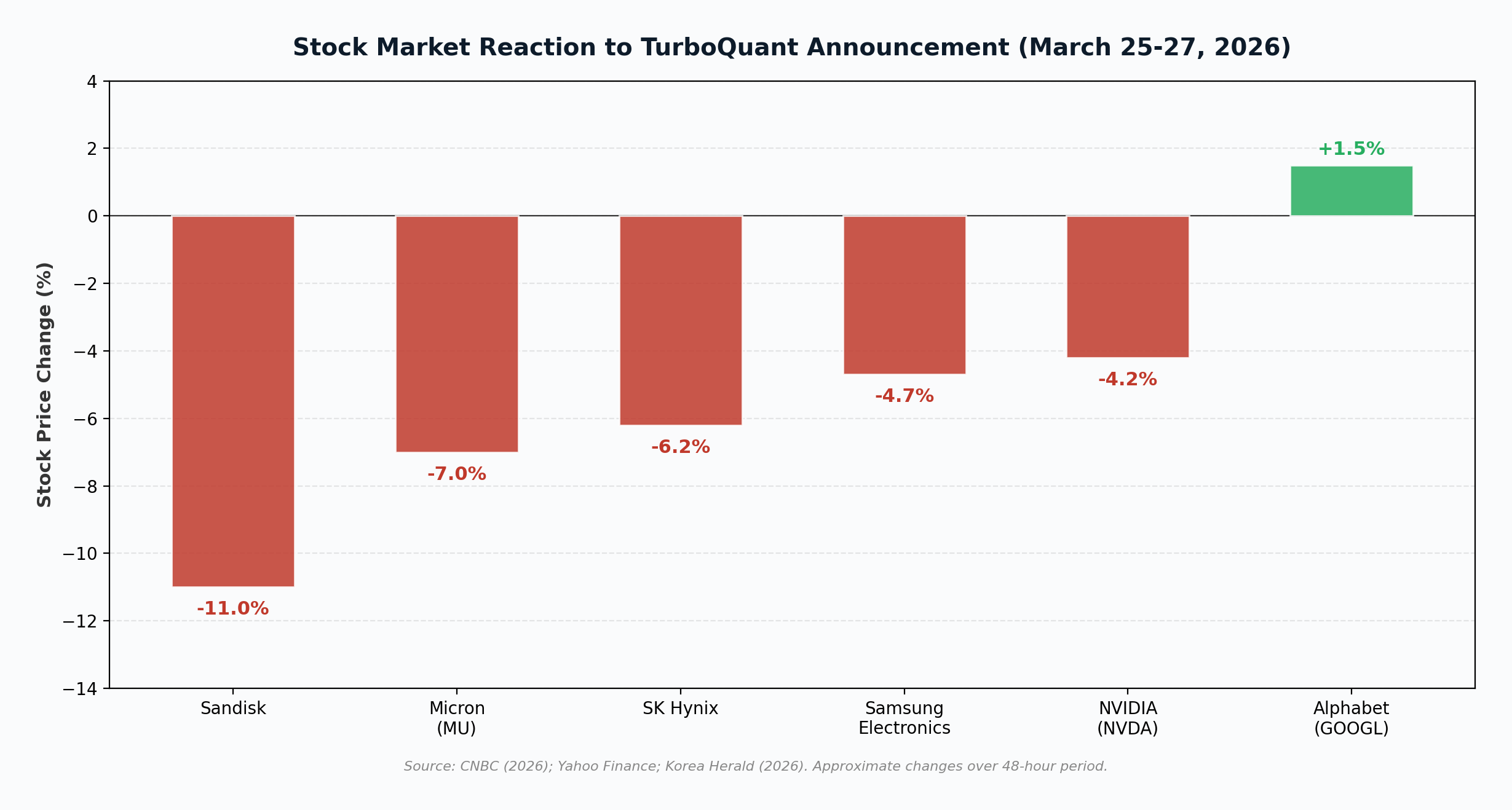
The fear driving the sell-off is straightforward: if AI systems can achieve the same performance with one-sixth the memory, data centers may need dramatically fewer memory chips than previously projected. For companies like Micron, whose premium HBM3E chips have been the cornerstone of the AI memory “supercycle,” this threatens the scarcity narrative that has driven record pricing and margins.
However, not all analysts share the bearish view. Ray Wang, a memory analyst at Semi, argued that addressing the KV cache bottleneck would enhance overall AI hardware capabilities, ultimately driving demand for more powerful systems. “When you tackle a bottleneck, you enhance the capabilities of AI hardware. As models gain strength, they will necessitate superior hardware to support them,” he told CNBC (CNBC, 2026). This “Jevons paradox” argument suggests that making AI cheaper to run could expand total demand enough to offset the per-unit memory reduction.
Important Context
TurboQuant targets inference memory only, not training memory. Training large language models still requires massive amounts of RAM, and the algorithm does not address that cost. Additionally, TurboQuant remains a lab breakthrough that has not yet been deployed broadly in production systems. The gap between published benchmarks and real-world implementation at scale is where many promising algorithms have stalled (TechCrunch, 2026).
Why This Is a Game Changer
Several properties distinguish TurboQuant from previous compression attempts and justify the extraordinary market attention it has received.
- Zero accuracy loss at extreme compression: Previous KV cache compression methods involved tradeoffs between memory savings and model quality. TurboQuant achieves 6x compression with provably unbiased estimates, meaning it introduces no systematic error. This is not an approximation; it is a mathematical guarantee rooted in information-theoretic lower bounds (Zandieh & Mirrokni, 2026).
- Training-free and universally applicable: The algorithm requires no retraining, no fine-tuning, and no dataset-specific calibration. It can be applied to any existing LLM immediately, from any provider, making it a platform-agnostic efficiency improvement for the entire AI industry (Help Net Security, 2026).
- Software solves a hardware problem: The AI industry has been pouring billions into manufacturing faster, denser memory chips to address the KV cache bottleneck. TurboQuant demonstrates that mathematics can achieve through software what the semiconductor industry has been struggling to achieve through physical scaling. This is a paradigm shift in how the industry thinks about AI infrastructure costs (Chronicle Journal, 2026).
- Immediate open-source adoption: Within days of publication, open-source Triton kernel implementations appeared for NVIDIA H100 and A100 GPUs, with fused PolarQuant and QJL operations that add negligible runtime overhead. The speed of community adoption signals strong practical viability (DEV Community, 2026).
- Dual application to KV cache and vector search: TurboQuant is not limited to LLM inference. Its compression properties apply equally to vector search, the technology underlying semantic search engines, recommendation systems, and RAG architectures. This broadens the impact surface far beyond chatbots and language models (Search Engine Land, 2026).
The comparison to DeepSeek, which disrupted AI economics by showing that competitive models could be trained at a fraction of the cost of Western alternatives, is instructive. DeepSeek demonstrated that training efficiency could be radically improved through clever engineering. TurboQuant makes the same argument for inference efficiency. Together, they represent a broader trend: the center of gravity in AI economics is shifting from raw hardware accumulation toward mathematical and software optimization.
What Comes Next
The critical question is whether TurboQuant’s lab results translate to production-scale deployment. The algorithm will be formally presented at ICLR 2026 next month, where it will face scrutiny from the broader research community. Two indicators will determine whether the current market reaction is warranted or overblown: first, whether hyperscalers like Amazon and Microsoft adopt TurboQuant or release comparable algorithms; and second, the pace at which context windows continue to expand. If context windows grow from 1 million to 10 million tokens, the 6x efficiency gain will be absorbed by the increased memory demand, and physical memory chip demand may return to its previous trajectory (Chronicle Journal, 2026).
For now, TurboQuant represents something rare in AI research: a single algorithm that simultaneously improves speed, reduces cost, maintains quality, and requires no changes to the underlying model. Whether it ultimately reshapes the AI infrastructure market or gets absorbed into a broader toolkit of optimization techniques, the underlying message is clear. The most important breakthroughs in AI may no longer be measured in parameter counts or training budgets. They may be measured in the elegance of the mathematics that makes everything else cheaper.
References
Chronicle Journal. (2026, March 31). The compression crisis: Google’s TurboQuant breakthrough wipes billions from Micron and memory giants. http://markets.chroniclejournal.com/chroniclejournal/article/marketminute-2026-3-31-the-compression-crisis
CNBC. (2026, March 26). A Google AI breakthrough is pressuring memory chip stocks. https://www.cnbc.com/2026/03/26/google-ai-turboquant-memory-chip-stocks-samsung-micron.html
DEV Community. (2026, March 29). TurboQuant: What developers need to know about Google’s KV cache compression. https://dev.to/arshtechpro/turboquant-what-developers-need-to-know-about-googles-kv-cache-compression-eeg
Help Net Security. (2026, March 25). Google’s TurboQuant cuts AI memory use without losing accuracy. https://www.helpnetsecurity.com/2026/03/25/google-turboquant-ai-model-compression/
ibl.ai. (2026, March 27). Google’s TurboQuant cuts AI memory 6x. https://ibl.ai/blog/turboquant-ai-memory-compression-own-infrastructure
Korea Herald. (2026, March 27). Google’s TurboQuant jolts memory stocks, but demand outlook seen intact. https://www.koreaherald.com/article/10704478
MIT Sloan Management Review Middle East. (2026, March 27). Google unveils TurboQuant, a new AI memory compression algorithm. https://www.mitsloanme.com/article/google-unveils-turboquant-a-new-ai-memory-compression-algorithm/
Pulse 2.0. (2026, March 30). Google: TurboQuant breakthrough shows 8x AI memory speed gains and major cost reductions. https://pulse2.com/google-turboquant-breakthrough-shows-8x-ai-memory-speed-gains-and-major-cost-reductions/
Search Engine Land. (2026, March 31). New Google TurboQuant algorithm improves vector search speed. https://searchengineland.com/google-turboquant-algorithm-vector-search-472977
TechCrunch. (2026, March 26). Google unveils TurboQuant, a new AI memory compression algorithm. https://techcrunch.com/2026/03/25/google-turboquant-ai-memory-compression-silicon-valley-pied-piper/
The Next Web. (2026, March 26). Google’s TurboQuant compresses AI memory by 6x, rattles chip stocks. https://thenextweb.com/news/google-turboquant-ai-compression-memory-stocks
Tom’s Hardware. (2026, March 25). Google’s TurboQuant reduces AI LLM cache memory capacity requirements by at least six times. https://www.tomshardware.com/tech-industry/artificial-intelligence/googles-turboquant-compresses-llm-kv-caches-to-3-bits-with-no-accuracy-loss
Zandieh, A., & Mirrokni, V. (2026). TurboQuant: Quantizing high-dimensional vectors with optimal distortion for efficient KV cache and vector search. Proceedings of the International Conference on Learning Representations (ICLR 2026).